![[RSS]](../theme/image/rss.png)
Porting a DaCHS SIAv1 service to SIAP2
Ten years after, let me talk about SIAP version 2.
In December 2015, the IVOA made Simple Image Access Version 2.0 (hereafter: SIAv2) a Recommendation (that is: the standard you should be following). I am fairly sure that most people into computers would have understood that as “Don't do Simple Image Access version 1 (SIAv1) any more“. As of ten years ago.
This is not how things worked out. Actually, to this day new SIAv1 services still come online. In the talk about major version transitions I gave in College Park last June, I remark that 20% of the registered SIAv1 services were younger than 30 months.
There are many reasons why obsoleting SIAv1 has not worked (yet); very frankly, I had rather fiercely argued we don't want SIAv2 at all on grounds that Obscore is all you need to discover products of observations.
But since it's there now I feel I should do something for its adoption, beginning with not pushing out any new SIAv1 services myself. So, when a data provider sent me an RD they built from a previous one and it would have published a new SIAv1 service, I thought this was the time to start updating my own services.
The next step then is to encourage DaCHS adopters to help out, too, that is, to port over their RDs from doing SIAP version 1 to doing SIAP version 2[1]. That's why I am writing this blog post.
Going From SIAv1 to SIAv2 in 11 Moderately Difficult Steps
Since the output table schema (and quite a bit beyond that) changed between the two version, the port is not entirely trivial; if it were, we wouldn't have done a major version (i.e., breaking) change in the first place. But I'd argue it's quite doable when two conditions are met:
- You have a DaCHS version 2.8 or later (if not, you should upgrade anyway).
- You are not using siapCutoutCore right now; what this does is hard to replicate in SIAv2 (because positional constraints are now optional), and so if you want to keep the auto-cutout functionality, you probably are stuck on SIAv1.
That said, here's my recipe:
Change the mixin on the table that keeps the image metadata. So far, you probably had mixin="//siap#pgs". Drop this and add:
<mixin have_bandpass_id="True">//siap2#pgs</mixin>
to the table body instead. If you really have no bandpass you would like to mention, you can leave out the attribute definition.
Change the obscore mixin in the table body if you did an obscore publication (skip this step if not). With SIAv2, write instead:
<mixin preview="access_url || '?preview=True'" >//obscore#publishObscoreLike</mixin>
It is really simple now because SIAv2 just re-uses the obscore schema.
Keep your old mixin definition in a scratch pad (or the version control history at least), because it will help you when you fill out the parameters to //siap2#setMeta.
Change any index statements for standard columns you may have; the column names are completely different between SIAv1 and SIAv2. Classic examples include:
- bandpassId is bandpass_id (if available)
- bandpassLo is em_min
- bandpassHi is em_max
- dateObs should become indexes on t_min and t_max.
If your table is small enough that you managed without indexes so far, don't bother creating new ones.
Check custom extension fields for whether they are now in core SIAv2. The classic case is exposure time, which was missing in SIAv1. Just drop your custom column definition(s).
If there is datalink on the SIAP table, you will have to change its definition, too; the relevant column is now obs_publisher_did. If your datalink service has the id dl, the result of the operation would be this:
<meta name="_associatedDatalinkService"> <meta name="serviceId">dl</meta> <meta name="idColumn">obs_publisher_did</meta> </meta>
This may lead to datalink failures in DaCHS < 2.13 (in that the datasets are no longer found). If this bites you, let me know.
Fix the rowmaker for the SIAP table. For the computePGS and getBandFromFilter apply, just add a 2 to their procDef references, so that these become //siap2#computePGS and //siap2#getBandFromFilter (if applicable).
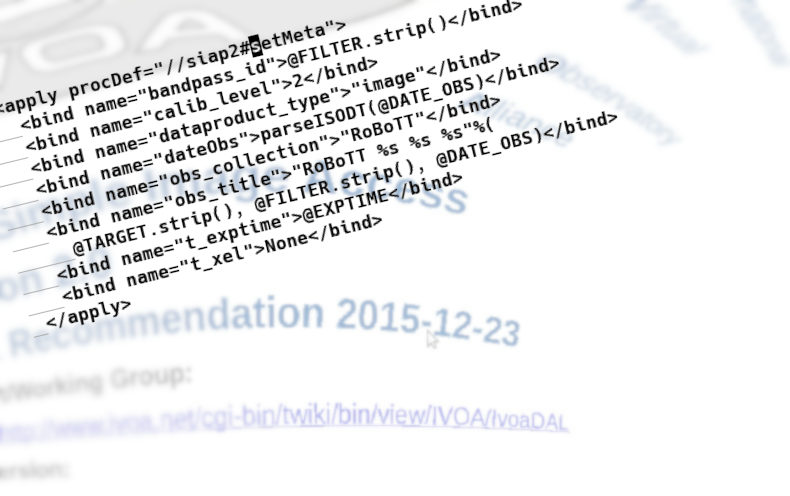
The main work is going from //siap#setMeta to //siap2#setMeta, because their parameter sets are somewhat different, although they do map to each other to some degree.
The way to do the migration is to go through SIAv2's setMeta's parameter list in the reference documentation and identify the old parameters, or take the values from your obscore definition. Once you are past this point, you have done the heavy lifiting.
(For completeness, let me mention that you will probably get away with dropping pixflags and keeping the other parameters as they are, as there is some compatibility glue; but you'd miss setting up extra SIAv2 metadata, and that would be a shame).
Experimentally run dachs imp. This will probably fail because there are references to old column names in, say, service definitions. Resolve these based on the names you used in setMeta (which largely double as the column names). When you made DaCHS accept your refurbished RD and have run the import, use dachs info to catch metadata items you have missed.
If you used a shared core for both a service with the siap.xml renderer and the web form service, move that core into the web form service. Use //siap2#humanInput for the new positional constraint, and drop the #protoInput, if it is there, because it is no longer needed.
The protocol service has to have allowed="siap2.xml", and its new core is:
<dbCore queriedTable="main"> <FEED source="//siap2#parameters"/> </dbCore>
Replace "main" with whatever your table is called, and add any custom parameters you would like to have.
In your regression tests (you have some, don't you?), change the renderers in the URIs (siap2.xml instead of siap.xml), and change POS and SIZE into POS="CIRCLE ..."; it is likely that you will also have to change column names in the assertions.
In your publish element(s), change render="siap.xml" to render="siap2.xml"
Run dachs pub q to tell the Registry that your access URL has changed.
That's it.
I would argue this is time well spent. Even if one day there will be a successor to SIAv2 (and I do hope there will be one), it is highly likely that its metadata schema will align very well with obscore's, and hence most of the work you just did will put you in a very good position to switch to DAP with just a few keystrokes.
| [1] | If you have built SIA services with DaCHS 2.8 (2023) or later using dachs start, you will already have a SIAv2 service; see the discussion in the pertaining release notes. |