
![[RSS]](./theme/image/rss.png)

A little ego booster in DAL I: Baptiste and Chloe discuss a feature for incremental harvesting of remote databases using odbcGrammar that I have implanted into DaCHS late last year.
This morning at seven CEST the first Interop of this year started: It's time again for everyone involved in the VO to come together, tell each other what happened since the last Interop and plan for the next steps. The meeting is purely digital again, and again the schedule is a bit crazy in order to evenly spread time painsj across the globe: there are sessions in the relatively early morning CET, in the late afternoon, and fairly late at night.
Fairly late at night (by my standards) is now, when I'm listening to the talks in a session of the Data Access Layer working group trying to work out how to do multiple cutouts in one request using SODA, something I've been rather skeptical about while we were coming up with the spec in the mid-2010s: Going from “single value“ to “sequence“ generally complicates matters by something like an order of magnitudes, and with HTTP 1.1 – which lets you run multiple requests in a single connection – doing multiple requests is cheap.
In contrast, SODA doesn't really say what a service should do if, say, there are multiple positions in a cutout request: should the regions be merged (that's what DaCHS does)? Should multiple images come back? If so, how: in a tar, in a multi-extension FITS, in some other way? What happens if you give both multiple positional and spectral ranges: should there be one result per element of the cartesian product? And if it works that way: should clients have a chance to figure out what combination of parameters produced which result dataset?
In all that mess, it's gratifying to see that my compromise proposal from way back when – if we do multi-cutout, let's do it by uploading a table specifying one cutout, including a label, per row – to be floated again. But very frankly: My vote would still be to deprecate repeated POS, CIRCLE, BAND, and friends in SODA: requests are cheap these days.
Oh, and while I'm confessing emotions of perhaps not entirely unselfish gratification: I still rejoice when I see DaCHS applications discussed in public, as Chloé and Baptiste did in their talk.
Update at 2022-04-27, Morning
The “virtual” Interop may not be quite as exciting as the real thing, but at least the jetlag is back.
Yesterday at midnight I gave a talk on requirements and validators, which really was an elaboration of some of the ideas I developed on this blog a month ago. If I may say so myself, I've grown fond of the classification of MUST-s into, in the end, items the machines need, items the users need, admonishments for implementors, and items that we believe the future may need. I'm sure there are more, but even for these I found it remarkable that the less will immediately break if someone violates a piece of a spec, the more important validation becomes. This again is one of these thoughts that feel as if someone probably has pondered them a lot more deeply before…
I also was really happy about Mark's pitch for validating specifications themselves that kept me awake until one a.m. CEST. In my authoring system ivoatex, I've introduced a hook to allow for a test target, and Mark kindly supported that effort by adding an xsdvalidate subcommand to the excellent stilts. The ivoatex documentation then grew some advice on what and how to test; in case you're writing or maintaining IVOA specs: do have a look. Mark's talk has a few great examples where spec-time validation would have saved a lot of effort and embarrassment.
Only six hours later, I was back in <expletive deleted> zoom to listen to the Grid session, which again featured Mark, apparently unfazed by the lack of sleep, talking about (potentially) federated authentication outside of the browser (which is something I really want for persistent TAP uploads).
And then there was the joint time domain/radio session. The slides are not yet there, but once they are, do yourself a favour and at least look at the beautiful images Dougal showed – Radio by now can make about as pretty pictures as Optical – and Alan's talk with the hypnotic sensitivity maps that again showed that low-frequency radio astronomy, seen from outside, is even more of an arcane art than is its high-frequency sibling.
Update at 2022-04-27, late evening
For me, this Interop has a strong proper motion slant. In this afternoon's Apps session, I tried to sell an extension to COOSYS I've wanted for a long time, just enough to do epoch propagation.
You see, ever since my first serious contribution to the VO standards universe, the proposal on doing STC annotation in VOTable in 2010, failed miserably because almost nobody took it up, I have struggled to still somehow get enough annotation added to VOTables to let clients apply proper motions automatically.
Given there are now data models for Coordinates and what we call Measurements (which roughly is errors and, well, a bit of physics) on the way, I figured this might be a good time to finally fix the COOSYS VOTable element. For one, data centers will revisit the STC annotation anyway if the models and the VOTable data model annotation will pass the reviews, and producing an improved COOSYS would then almost come for free.
But I can't lie: after the experiences of the past I'd also love to have a fallback position in case we spend another ten years on data models and annotations without getting anywhere. 25 years after the VO's birth epoch (if you will) of J2000.0, many stars have already moved of order of an arcsecond from where our first big catalogues saw them, and so we can ill afford to wait these extra ten years.
Not surprisingly, the proposal resulted in quite a bit of pushback, perhaps even a bit more than I had expected. Well: I should have given this talk years ago.
The proper motion topic will come back tomorrow in the second DAL session, when I will talk about ADQL user defined functions to do epoch propagation. This talk will feature one of the prettier plots I've produced in the last few months:
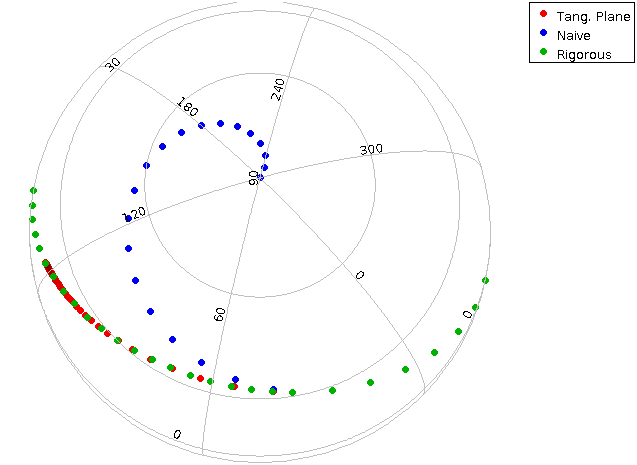
What happens if you propagate positions when all you have are proper motions (i.e., no parallaxes and no distances) and you do that naively (blue), in the tangential plane (red), and under the assumption of a purely tangential motion. The lecture notes tell you how to come up with the data plotted here.
I think I can safely predict you will read more about some of these UDFs on this very blog later this year.
Update 2022-04-28, late evening
Today felt the most conferency so far for this Interop, and perhaps for any “virtual conference“ I've attended. I believe there's a technical reason for that. After the second proper motion-flavoured talk I've just mentioned – that was still using, sigh, zoom –, things mostly happened in gathertown, a platform you can actually walk around in, stand together and don't always talk on stage as in zoom. Fervently believing in the mantra of “protocols, not platforms” (of course: this is the VO), I shouldn't be saying this, but: I actually like gathertown.
And so I guess we made quite a bit of progress in little side meetings and a hackathon on things like LineTAP (which, I hope, will bring all the rich data on spectral lines from VAMDC to the VO); how to let people have continuous integration checks against their Jupyter notebooks to notice in time when we're breaking something (my recent brown-bag pyvo bug that has somwhat started this was actually mentioned as a positive example in a talk (slide 19); and: it turned out I'm not the only notebook skeptic on this planet!); how we ought to define “facility” and “instrument“ in Obscore and the Registry (and, probably particularly insiduously, in SSAP, where what's called “facility“ there should probably be what's called “instrument“ elsewhere – sigh), a topic we already had touched yesterday, which in turn has resulted in Tamara's mail; an interesting service DaCHS operators want to run that would return PDF files as what DaCHS calls a “product” (which would normally be a thing like a FITS file); and then some more, including, of course, idle chatting.
That was almost as good as an actual meeting.
Update 2022-04-29, afternoon
This morning, I chaired a nice and lively Semantics session, where I talked about the move of our Vocabulary maintenance to github. That particular thing did not elicit a lot of comments, not even when I extended an invitation to perhaps amend Vocabularies in the VO 2 in other weys. I'll take that as some sort of reassurance that I did a reasonably good job designing that thing, although I cannot entirely rule out that people just did not have enough time to find the warts.
One thing I will call out at tonight's closing penary is Stéphane's talk on vocabularies in EPN-TAP. The way he was looking at the various word lists involved in that standard, looking at what “just works“, where the concepts are probably too special to worry about, and then the clumsy space in between – where there are or should be vocabularies that almost, but not quite fit – was exemplary. I'm looking forward to followups on the mailing lists, trying to work out where we can perhaps align different concept hierarchies so we spare implementors duplicate efforts. And figuring out where that's impossible, too expensive, or in other ways undesirable, and where the problems are. I suppose there's a lot to be learned from that.
Another high point was the identification of Wikidata as a valuable resource for the never-ending story of creating identifiers for instruments and facilities in Baptiste's talk. There is some special gratification in making our activities matter beyond the VO, link our resources with the wider RDF world – and hack SPARQL.
What's left for me is the Registry session, where I will briefly report, in particular, on my most recent effort of getting rid of my venerable GloTS service by adding a table of TAP-queriable tables to RegTAP. Let's see what people say – but in the end the challenge will be to convince the other operators of RegTAP services to take up the proposed changes. The central challenge there is that part of it is built on MOCs, and while the ESAC registry is built on Postgres that can already taught to deal with them, the one at MAST is based on SQLServer, which, I think, cannot yet. Let's see.
Another thing I'm looking forward to is Hendrik's pitch for registring tutorials and similar educational material. I'd really like to see more stuff on VOTT, which is fed from such registrations.
Update 2022-04-29, late evening
Interops for me always have something of an ego trip when I see traces of my activities in other people's work. And I've just discovered such a trace in a place I had not expected it: Gilles' talk on extra metadata in service responses, where he showed metadata DaCHS returns with its TAP responses. This was in this morning's session of the Data Curation and Preservation interest group that, I have to admit, I skipped in favour of a proper breakfast without a screen in front of me.
And he touched a topic that's dear to my heart, too. Really, I've been struggling to give applications enough metadata such that they can simply spit out a bunch of BibTeX for the sources used in a particular VO workflow for quite a while. In typcial DaCHS responses, you will find a bibcode and often a link to BibTeX (example), and at least the container element I got standardised in DALI 1.1. Let's see what else we can specify so that machines can reliably extract such information: Authors? Technical contact addresses? Date and time of production (could be very relevant for evolving data)? Full provenance? Well: If you've ever missed some piece of metadata, this would be a good time to bring it up.
All that's left now is the reports of the Working Groups (which will be another midnight talk for me) and a bit of farewell ceremony. After that, I'll go to sleep, and so that's it for my Interop reporting.
Zitiert in: Another Virtual Interop