![[RSS]](../theme/image/rss.png)
A Data Publisher's Diary: Wide Images in DASCH
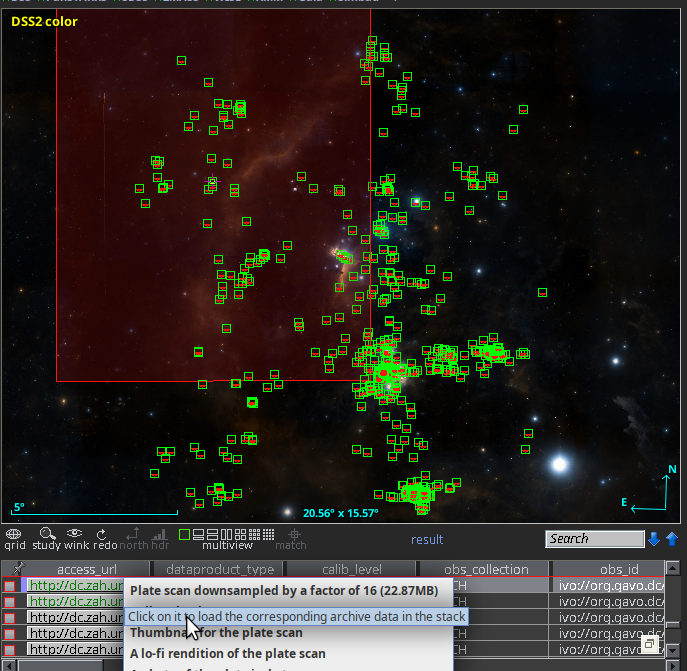
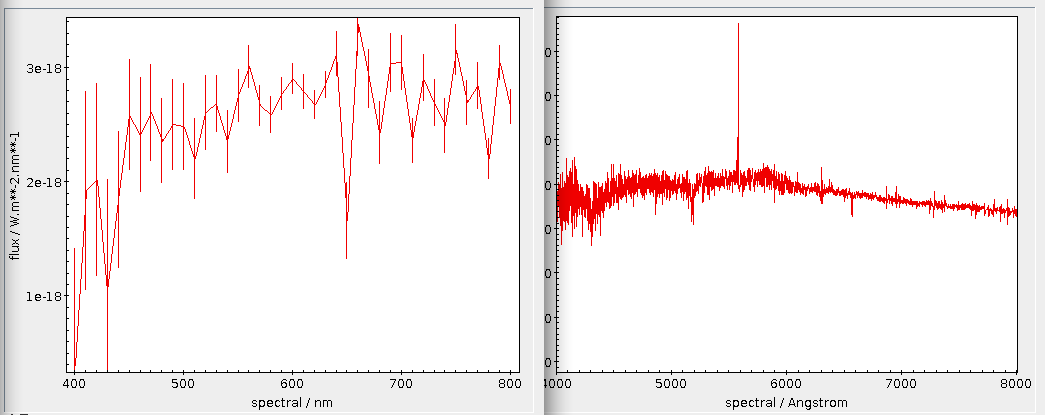
This is the new resonse when you query the DASCH SIAP service for Aladin's default view on the horsehead nebula. As you can see, at least the returned images no longer are distributed over half of the sky (note the size of the view).
The first reaction I got when the new DASCH in the VO service hit Aladin was: “your SIAP service is broken, it just dumps all images it has at me rather than honouring my positional constraint.”
I have to admit I was intially confused as well when an in-view search from Aladin came back with images with centres on almost half the sky as shown in my DASCH-in-Aladin illustration. But no, the computer did the right thing. The matching images in fact did have pixels in the field of view. They were just really wide field exposures, made to “patrol” large parts of the sky or to count meteors.
DASCH's own web interface keeps these plates out of the casual users' views, too. I am following this example now by having two tables, dasch.narrow_plates (the “narrow” here follows DASCH's nomenclature; of course, most plates in there would still count as wide-field in most other contexts) and dasch.wide_plates. And because the wide plates are probably not very helpful to modern mainstream astronomers, only the narrow plates are searched by the SIAP2 service, and only they are included with obscore.
In addition to giving you a little glimpse into the decisions one has to make when running a data centre, I wrote this post because making a provisional (in the end, I will follow DASCH's classification, of course) split betwenn “wide” and “narrow” plates involved a bit of simple ADQL that may still be not totally obvious and hence may merit a few words.
My first realisation was that the problem is less one of pixel scale (it might also be) but of the large coverage. How do we figure out the coverage of the various instruments? Well, to be robust against errors in the astrometric calibration (these happen), let us average; and average over the area of the polygon we have in s_region, for which there is a convenient ADQL function. That is:
SELECT instrument_name, avg(area(s_region)) as meanarea FROM dasch.plates GROUP BY instrument_name
It is the power of ADQL aggregate function that for this characterisation of the data, you only need to download a few kilobytes, the equivalent of the following histogram and table:
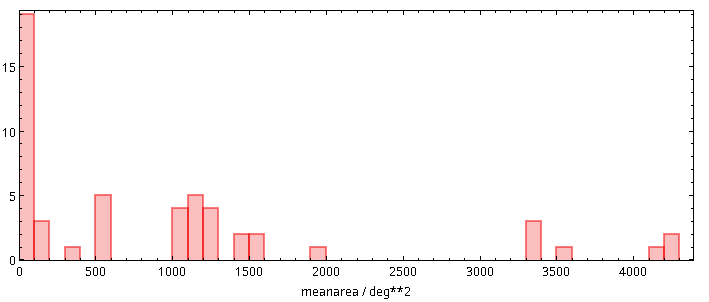
| Instrument Name | mean size [sqdeg] |
| Eastman Aero-Ektar K-24 Lens on a K-1... | |
| Cerro Tololo 4 meter | |
| Logbook Only. Pages without plates. | |
| Roe 6-inch | |
| Palomar Sky Survey (POSS) | |
| 1.5 inch Ross (short focus) | 4284.199799877725 |
| Patrol cameras | 4220.802442888225 |
| 1.5-inch Ross-Xpress | 4198.678060743206 |
| 2.8-inch Kodak Aero-Ektar | 3520.3257323233624 |
| KE Camera with Installed Rough Focus | 3387.5206396388453 |
| Eastman Aero-Ektar K-24 Lens on a K-1... | 3370.5283986677637 |
| Eastman Aero-Ektar K-24 Lens on a K-1... | 3365.539790633015 |
| 3 inch Perkin-Zeiss Lens | 1966.1600884072298 |
| 3 inch Ross-Tessar Lens | 1529.7113188540836 |
| 2.6-inch Zeiss-Tessar | 1516.7996790591587 |
| Air Force Camera | 1420.6928219265849 |
| K-19 Air Force Camera | 1414.074101143854 |
| 1.5 in Cooke "Long Focus" | 1220.3028263587332 |
| 1 in Cook Lens #832 Series renamed fr... | 1215.1434235932702 |
| 1-inch | 1209.8102811770807 |
| 1.5-inch Cooke Lenses | 1209.7721123964636 |
| 2.5 inch Cooke Lens | 1160.1641223648048 |
| 2.5-inch Ross Portrait Lens | 1137.0908812243645 |
| Damons South Yellow | 1106.5016573891376 |
| Damons South Red | 1103.327982978934 |
| Damons North Red | 1101.8455616455205 |
| Damons North Blue | 1093.8380971825375 |
| Damons North Yellow | 1092.9407550755682 |
| New Cooke Lens | 1087.918570304363 |
| Damons South Blue | 1081.7800084709982 |
| 2.5 inch Voigtlander (Little Bache or... | 548.7147592220762 |
| NULL | 534.9269386355818 |
| 3-inch Ross Fecker | 529.9219051692568 |
| 3-inch Ross | 506.6278856912204 |
| 3-inch Elmer Ross | 503.7932693652602 |
| 4-inch Ross Lundin | 310.7279860552893 |
| 4-inch Cooke (1-327) | 132.690621660727 |
| 4-inch Cooke Lens | 129.39637516917298 |
| 8-inch Bache Doublet | 113.96821604869973 |
| 10-inch Metcalf Triplet | 99.24964308212328 |
| 4-inch Voightlander Lens | 98.07368690379751 |
| 8-inch Draper Doublet | 94.57937153909593 |
| 8-inch Ross Lundin | 94.5685388440282 |
| 8-inch Brashear Lens | 37.40061588712761 |
| 16-inch Metcalf Doublet (Refigured af... | 33.61565584978583 |
| 24-33 in Jewett Schmidt | 32.95324914757339 |
| Asiago Observatory 92/67 cm Schmidt | 32.71623733985344 |
| 12-inch Metcalf Doublet | 31.35112644688316 |
| 24-inch Bruce Doublet | 22.10390937657793 |
| 7.5-inch Cooke/Clark Refractor at Mar... | 14.625992810622787 |
| Positives | 12.600189007151709 |
| YSO Double Astrograph | 10.770798601877804 |
| 32-36 inch BakerSchmidt 10 1/2 inch r... | 10.675406541122827 |
| 13-inch Boyden Refractor | 6.409447066606171 |
| 11-inch Draper Refractor | 5.134521254785461 |
| 24-inch Clark Reflector | 3.191361603405415 |
| Lowel 40 inch reflector | 1.213284257086087 |
| 200 inch Hale Telescope | 0.18792105301170514 |
For the instruments with an empty mean size, no astrometric calibrations have been created yet. To get a feeling for what these numbers mean, recall that the celestial sphere has an area of 4 π rad², that is, 4⋅180²/π or 42'000 square degrees. So, some instruments here indeed covered 20% of the night sky in one go.
I was undecided between cutting at 150 (there is a fairly pronounced gap there) or at 50 (the gap there is even more pronounced) square degrees and provisionally went for 150 (note that this might still change in the coming days), mainly because of the distribution of the plates.
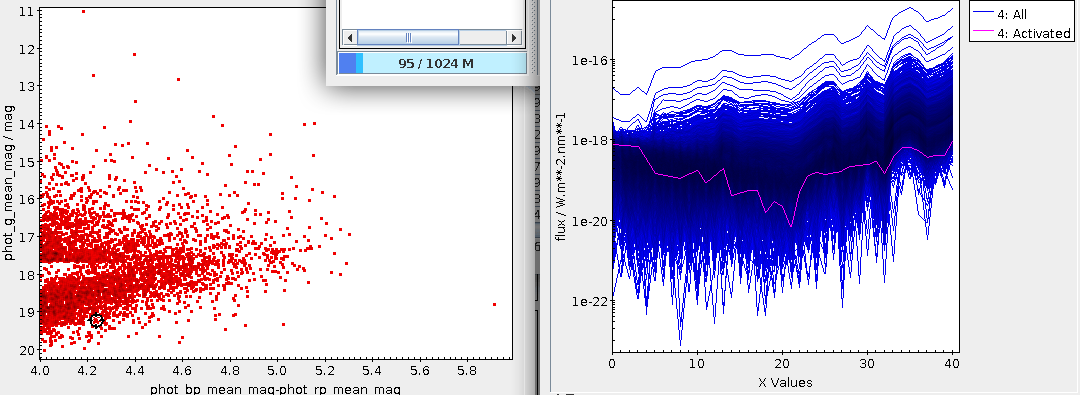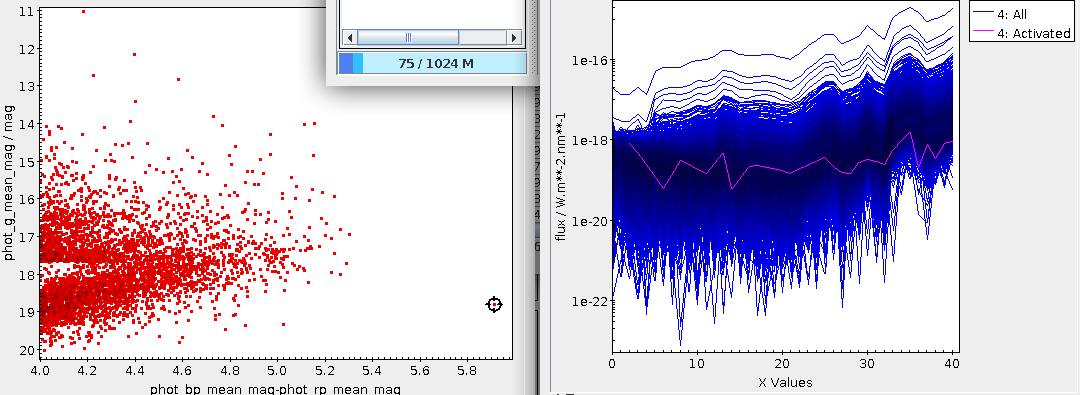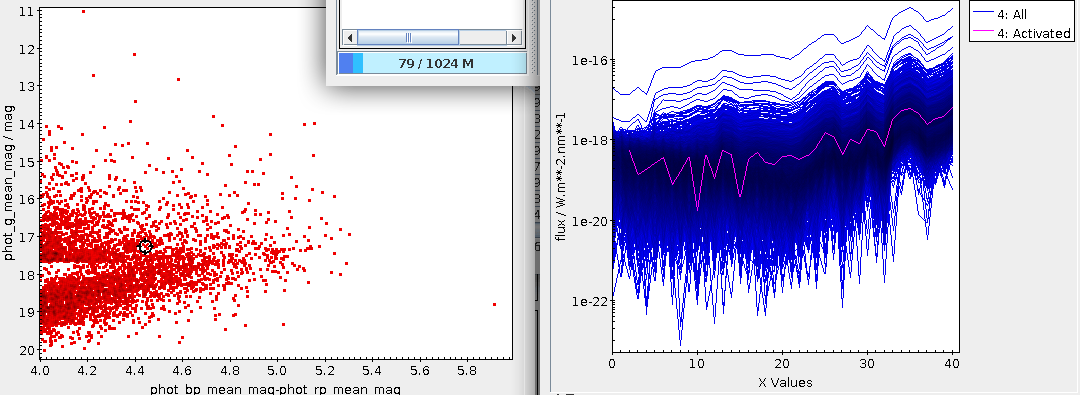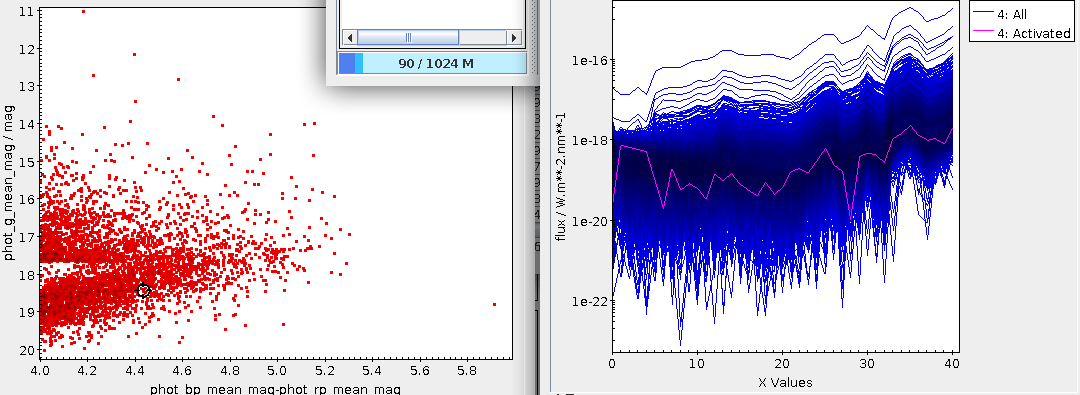
You see, the histogram above is about instruments. To assess the consequences of choosing one cut or the other, I would like to know how many images a given cut will remove from our SIAP and ObsTAP services. Well, aggregate functions to the rescue again:
SELECT ROUND(AREA(s_region)/100)*100 AS platebin, count(*) AS ct FROM dasch.plates GROUP BY platebin
To plot such a pre-computed histogram in TOPCAT, tell the histogram plot window to use ct as the weight, and you will see something like this:
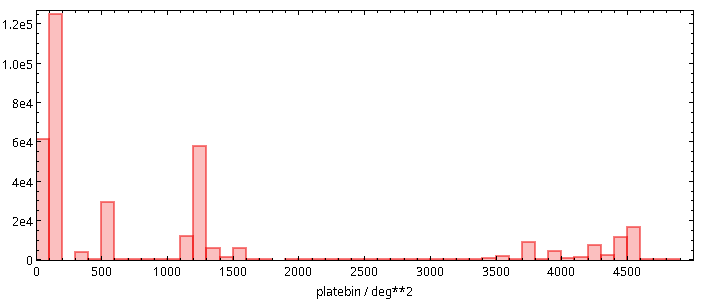
It was this histogram that made me pick 150 deg² as the cutoff point for what should be discoverable in all-VO queries: I simply wanted to retain the plates in the second bar from left.