![[RSS]](../theme/image/rss.png)
The Loneliest Star in the Sky
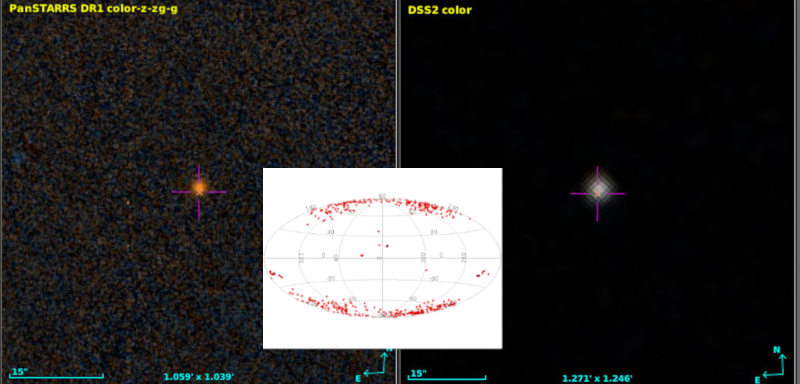
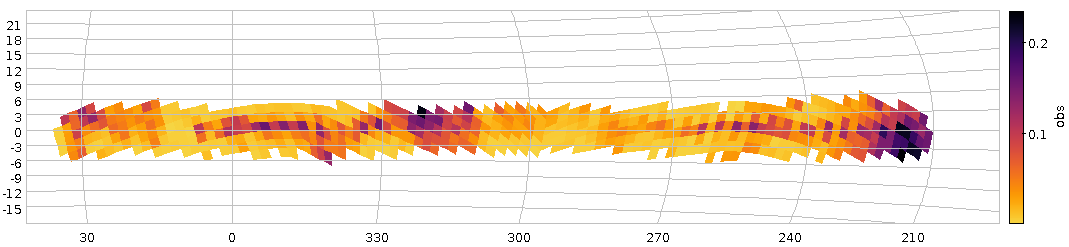
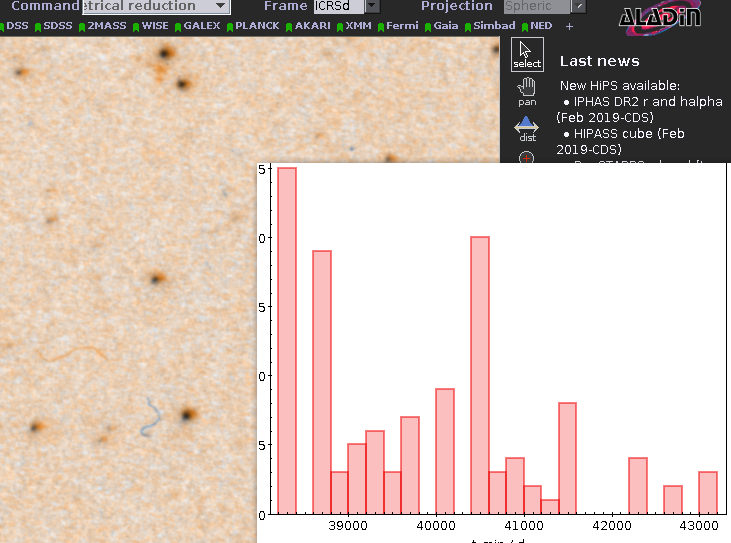
The loneliest star in the sky on the left, and on the right a somewhat more lonelier one (it's explained in the text). The inset shows the distribution of the 500 loneliest stars on the whole sky in Galactic coordinates.
In early December, the object catalogue of Gaia's data release 3 was published (“eDR3“), and I've been busy in various ways on this data off and on since then – see, for instance, the The Case of the disappearing bits on this blog.
One of the things I have missed when advising people on projects with previous Gaia data releases is a table that, for every object, gives the nearest neighbour. And so for this release I've created it and christened it, perhaps just a bit over-grandiosely, “Gaia eDR3 Autocorrelation”. Technically, it is just a long (1811709771 rows, to be precise) list of pairs of Gaia eDR3 source ids, the ids of their nearest neighbour, and a spherical distance between.
This kind of data is useful for many applications, mostly when looking for objects that are close together or (more often) things that fail for such close pairs for a wide variety of reasons. I have taken some pains to not only have close neighbours, though, because sometimes you may want specifically objects far away from others.
As in the case of this article's featured image: The loneliest star in the sky (as seen by Gaia, that is) is eDR3 6049144983226879232, which is 4.3 arcminutes from its neighbour, 6049144021153793024, which in turn is the second-loneliest star in the sky. They are, perhaps a bit surprisingly, in Ophiuchus (and thus fairly close to the Milky Way plane), and (probably) only about 150 parsec from Earth. Doesn't sound too lonely, hm? Turns out: these stars are lonely because dust clouds blot out all their neighbours.
Rank three is in another dust cloud, this time in Taurus, and so it continues in low Galactic latitude to rank 8 (4402975278134691456) at Galactic latitude 36.79 degrees; visualising the thing, it turns out it's again in a dark cloud. What about rank 23 at 83.92 Galactic (3954600105683842048)? That's probably bona-fide, or at least it doesn't look very dusty in the either DSS or PanSTARRS. Coryn (see below) estimates it's about 1100 parsec away. More than 1 kpc above the galactic disk: that's more what I had expected for lonely stars.
Looking at the whole distribution of the 500 loneliest stars (inset above), things return a bit more to what I had expected: Most of them are around the galactic poles, where the stellar density is low.
So: How did I find these objects? Here's the ADQL query I've used:
SELECT TOP 500
ra, dec, source_id, phot_g_mean_mag, ruwe,
r_med_photogeo,
partner_id, dist,
COORD2(gavo_transform('ICRS', 'GALACTIC',
point(ra, dec))) AS glat
FROM
gedr3dist.litewithdist
NATURAL JOIN gedr3auto.main
ORDER BY dist DESC
– run this on the TAP server at http://dc.g-vo.org/tap (don't be shy, it's a cheap query).
Most of this should be familiar to you if you've worked through the first pages of ADQL course. There's two ADQL things I'd like to advertise while I have your attention:
- NATURAL JOIN is like a JOIN USING, except that the database auto-selects what column(s) to join on by matching the columns that have the same name. This is a convenient way to join tables designed to be joined (as they are here). And it probably won't work at all if the tables haven't been designed for that.
- The messy stuff with GALACTIC in it. Coordinate transformations had a bad start in ADQL; the original designers hoped they could hide much of this; and it's rarely a good idea in science tools to hide complexity essentially everyone has to deal with. To get back on track in this field, DaCHS servers since about version 1.4 have been offering a user defined function gavo_transfrom that can transform (within reason) between a number of popular reference frames. You will find more on it in the server's capabilities (in TOPCAT: the “service” tab). What is happening in the query is: I'm making a Point out of the RA and Dec given in the catalogue, tell the transform function it's in ICRS and ask it to make Galactic coordinates from it, and then take the second element of the result: the latitude.
And what about the gedr3dist.litewithdist table? That doesn't look a lot like the gaiaedr3.gaiasource we're supposed to query for eDR3?
Well, as for DR2, I'm again only carrying a “lite” version of the Gaia catalogue in GAVO's Heidelberg data center, stripped down to the columns you absolutely cannot live without even for the most gung-ho science; it's called gaia.edr3lite.
But then my impression is that almost everyone wants distances and then hacks something to make Gaia's parallax work for them. That's a bad idea as the SNR goes down to levels very common in the Gaia result catalogue (see 2020arXiv201205220B if you don't take my word for it). Hence, I'm offering a pre-joined view (a virtual table, if you will) with the carefully estimated distances from Coryn Bailer-Jones, and that's this gedr3dist.litewithdist. Whenever you're doing something with eDR3 and distances, this is where I'd point you first.
Oh, and I should be mentioning that, of course, I figured out what is in dust clouds and what is not with TOPCAT and Aladin as in our tutorial TOPCAT and Aladin working together (which needs a bit of an update, but you'll figure it out).
There's a lot more fun to be had with this (depending on what you find fun in). What about finding the 10 arcsec-pairs with the least different luminosities (which might actually be useful for testing some optics)? Try this:
SELECT TOP 300
a.source_id, partner_id, dist,
a.phot_g_mean_mag AS source_mag,
b.phot_g_mean_mag AS partner_mag,
abs(a.phot_g_mean_mag-b.phot_g_mean_mag) AS magdiff
FROM gedr3auto.main
NATURAL JOIN gaia.edr3lite AS a
JOIN gaia.edr3lite AS b
ON (partner_id=b.source_id)
WHERE
dist BETWEEN 9.999/3600 AND 10.001/3600
AND a.phot_g_mean_mag IS NOT NULL
AND b.phot_g_mean_mag IS NOT NULL
ORDER BY magdiff ASC
– this one takes a bit longer, as there's many 10 arcsec-pairs in eDR3; the query above looks at 84690 of them. Of course, this only returns really faint pairs, and given the errors stars that weak have they're probably not all that equal-luminosity as that. But fixing all that is left as an exercise to the reader. Given there's the RP and BP magnitude columns, what about looking for the most colourful pair with a given separation?
Acknowledgement: I couldn't have coolly mumbled about Ophiuchus or Taurus without the SCS service ivo://cds.vizier/vi/42 (”Identification of a Constellation From Position, Roman 1982”).
Update [2021-02-05]: I discovered an extra twist to this story: Voyager 1 is currently flying towards Ophiuchus (or so Wikipedia claims). With an industrial size package of artistic licence you could say: It's coming to keep the loneliest star company. But of course: by the time Voyager will be 150 pc from earth, eDR3 6049144983226879232 will quite certainly have left Ophiuchus (and Voyager will be in a completely different part of our sky, that wouldn't look familar to us at all) – so, I'm afraid apart from a nice conincidence in this very moment (galactically speaking), this whole thing won't be Hollywood material.