2018-01-19
Markus Demleitner
RegTAP is one of those
standards that a scientist will normally not see – it works in the
background and makes, for instance, TOPCAT display the Cone Search
services matching some key words. And it's behind the services like
WIRR, our Web Interface to the Relational
Registry (“Relational Registry” being the official name for RegTAP) that
lets you do some interesting data discovery beyond what current clients
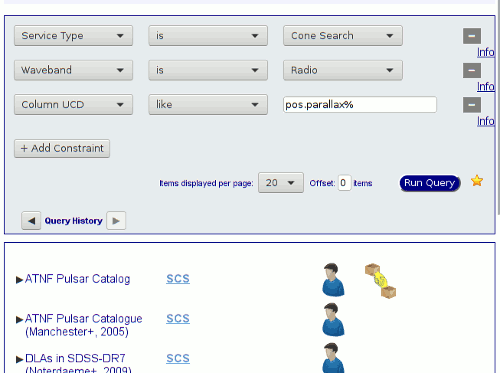
support. In the screenshot above, for instance (try it yourself),
I'm looking for cone search services having parallaxes presumably from
radio observations. You could now transmit the services you've found to,
say, TOPCAT or your own pyvo-based program to start querying them.
The key point this query is the use of UCDs – these let
services declare fairly unambiguously what kind of physics (if you take
that word with a grain of salt) they are talking about. In the example,
pos.parallax means, well, a parallax, and the percent character is a
wildcard (coming not from UCDs, but from ADQL). That wildcard is a good
idea here because without it we might miss things like
pos.parallax;obs and pos.parallax;stat.fit that people might
have used to distinguish “raw” and ”processed” estimates.
UCDs are great for data discovery. Really.
Sometimes, however, clicking around in menus just isn't good enough.
That's when you want the full power of RegTAP and write your very own
queries. The good news: If you know ADQL (and you should!), you're
halfway there already.
Here's one example of direct RegTAP use I came up with the other day.
The use case was discovering data collections that give the effective
temperatures of components of binary star systems.
If you check the UCD list, that “physics” translates into data that has
columns with UCDs of phys.temperature and meta.code.multip at
the same time. To translate that into a RegTAP query, have a look at the
tables that make up a RegTAP service: its ”schema”. Section 8 of the
standard
lists all the tables there are, and there's an ADASS poster that has an
image of the
schema with the more common columns illustrated. Oh, and if you're new
to RegTAP, you're probably better off briefly studying the examples
first to get a feeling for how RegTAP is supposed to work.
You will find that a pair of ivoid – the VO's global resource identifier
– and a per-resource table index uniquely identify a table within the
entire registry. So, an ADQL query to pick out all tables containing
temperatures and component identifiers would look like this:
SELECT DISTINCT ivoid, table_index
FROM
rr.table_column AS t1
JOIN rr.table_column AS t2
USING (ivoid, table_index)
WHERE t1.ucd='phys.temperature'
AND t2.ucd='meta.code.multip'
– the DISTINCT makes it so even tables that have lots of temperatures or
codes only turn up once in our result set, and the somewhat odd
self-join of the rr.table_column table with itself lets us say “make
sure the two columns are actually in the same table”. Note that you
could catch multi-table resources that define the components in one
table and the temperatures in another by just joining on ivoid rather
than ivoid and table_index.
You can run this query on any RegTAP endpoint: GAVO operates a small
network of mirrors behind http://reg.g-vo.org/tap, there's the ESAC one
at http://registry.euro-vo.org/regtap/tap, and STScI runs one at
http://vao.stsci.edu/RegTAP/TapService.aspx. Just use your usual TAP
client.
But granted, the result isn't terribly user-friendly: just identifiers
and number. We'd at least like to see the names and descriptions of the
tables so we know if the data is somehow relevant.
RegTAP is designed so you can locate the columns you would like to
retrieve or constrain and then just NATURAL JOIN everything together.
The table_description and table_name columns are in
rr.res_table, so all it takes to see them is to take the query above
and join its result like this:
SELECT table_name, table_description
FROM rr.res_table
NATURAL JOIN (
SELECT DISTINCT ivoid, table_index
FROM
rr.table_column AS t1
JOIN rr.table_column AS t2
USING (ivoid, table_index)
WHERE t1.ucd='phys.temperature'
AND t2.ucd='meta.code.multip') as q
If you try this, you'll see that we'd like to get the descriptions of
the resources embedding the tables, too in order to get an idea what we
can expect from a given data collection. And if we later want to find
services exposing the tables (WIRR is nice for that – try the ivoid
constraint –, but for this example all resources currently come from
VizieR, so you can directly use VizieR's TAP service to interact with
the tables), you want the ivoids. Easy: Just join rr.resource and pick
columns from there:
SELECT table_name, table_description, res_description, ivoid
FROM rr.res_table
NATURAL JOIN rr.resource
NATURAL JOIN (
SELECT DISTINCT ivoid, table_index
FROM
rr.table_column AS t1
JOIN rr.table_column AS t2
USING (ivoid, table_index)
WHERE t1.ucd='phys.temperature'
AND t2.ucd='meta.code.multip') as q
If you've made it this far and know a bit of ADQL, you probably have all
it really takes to solve really challenging data discovery problems – as
far as Registry metadata reaches, that is, which currently does not
include space-time coverage. But stay tuned, more on this soon.
In case you're looking for a more systematic introduction into the world
of the Registry and RegTAP, there are two... ouch. Can I really link to
Elsevier papers? Well, here goes: 2014A&C.....7..101D
(a.k.a. arXiv:1502.01186 on the
Registry as such and 2015A%26C....11...91D (a.k.a.
arXiv:1407.3083) mainly on
RegTAP.

![[RSS]](../theme/image/rss.png)

![[Screenshot: graphs and numbers]](/media/stats_gregory.png)