![[RSS]](../theme/image/rss.png)
What's new in DaCHS 2.10

About twice a year, I release a new version of our VO server package DaCHS; in keeping with tradition, this post summarises some of the more notable changes of the most recent release, DaCHS 2.10.
productTypeServed
The next version of VODataService will probably have a new element for service descriptions: productTypeServed. This allows operators to declare what sort of files will come out of a service: images, time series, spectra, or some of the more exotic stuff found in the IVOA product-type vocabulary (you can of course give multiple of these). More on where this is supposed to go is found my Interop talk on this. DaCHS 2.10 now lets you declare what to put there using a productTypeServed meta item.
For SIA and SSAP services, there is usually no need to give it, as RegTAP services will infer the right value from the service type. But if you serve, say, time series from SSAP, you can override the inference by saying something like:
<meta name="productTypeServed">timeseries</meta>
Where this really is important is in obscore, because you can serve any sort of product through a single obscore table. While you could manually declare what you serve by overriding obscore-extraevents in your userconfig RD, this may be brittle and will almost certainly get out of date. Instead, you can run dachs limits //obscore (and you should do that occasionally anyway if you have an obscore table). DaCHS will then feed the meta from what is in your table.
A related change is that where a piece of metadata is supposed to be drawn from a vocabulary, dachs val will now complain if you use some other identifier. As of DaCHS 2.10 the only metadata item controlled in this way is productTypeServed, though.
Registering Obscore Tables
Speaking about Obscore: I have long been unhappy about the way we register Obscore tables. Until now, they rode piggyback in the registry record of the TAP services they were queriable through. That was marignally acceptable as long as we did not have much VOResource metadata specific to the Obscore table. In the meantime, we have coverage in space, time, and spectrum, and there are several meaningful relationships that may be different for the obscore table than for the TAP service. And since 2019, we have the Discovering Data Collections Note that gives a sensible way to write dedicated registry records for obscore tables.
With the global dataset discovery (discussed here in February) that should come with pyVO 1.6 (and of course the productTypeServed thing just discussed), there even is a fairly pressing operational reason for having these dedicated obscore records. There is a draft of a longer treatment on the background on github (pre-built here) that I will probably upload into the IVOA document repository once the global discovery code has been merged. Incidentally, reviews of that draft before publication are most welcome.
But what this really means: If you have an obscore table, please run dachs pub //obscore after upgrading (and don't forget to run dachs limits //obscore after you do notable changes to your obscore table).
Ranking
Arguably the biggest single usability problem of the VO is <drumroll> sorting! Indeed, it is safe to assume that when someone types “Gaia DR3“ into any sort of search mask, they would like to find some way to query Gaia's gaia_source table (and then perhaps all kinds of other things, but that should reasonably be sorted below even mirrors of gaia_source. Regrettably, something like that is really hard to work out across the Registry outside of these very special cases.
Within a data centre, however, you can sensibly give an order to things. For DaCHS, that in particular concerns the order of tables in TAP clients and the order of the various entries on the root page. For instance, a recent TOPCAT will show the table browser on the GAVO data centre like this:
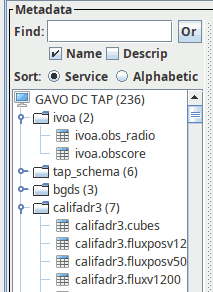
The idea is that obscore and TAP metadata are way up, followed by some data collections with (presumably) high scientific value for which we are the primary site; within the califadr3 schema, the tables are again sorted by relevance, as most people will be interested in the cubes first, the somewhat funky fluxpos tables second, and in the entirely nerdy flux tables last.
You can arrange this by assigning schema-rank metadata at the top level of an RD, and table-rank metadata to individual tables. In both cases, missing ranks default to 10'000, and the lower a rank, the higher up a schema or table will be shown. For instance, dfbsspec/q (if you wonder what that might be: see Byurakan to L2) has:
<resource schema="dfbsspec">
<meta name="schema-rank">100</meta>
...
<table id="spectra" onDisk="True" adql="True">
<meta name="table-rank">1</meta>
This will put dfbsspec fairly high up on the root page, and the spectra table above all others in the RD (which have the implicit table rank of 10'000).
Note that to make DaCHS notice your rank, you need to dachs pub the modified RDs so the ranks end up in DaCHS' dc.resources table; since the Registry does not much care for these ranks, this is a classic use case for the -k option that preserves the registry timestamp of the resource and will thus prevent a re-publication of the registry record (which wouldn't be a disaster either, but let's be good citizens). Ideally, you assign schema ranks to all the resources you care about in one go and then just say:
dachs pub -k ALL
The Obscore Radio Extension
While the details are still being discussed, there will be a radio extension to Obscore, and DaCHS 2.10 contains a prototype implementation for the current state of the specification (or my reading of it). Technically, it comprises a few columns useful for, in particular, interferometry data. If you have such data, take a look at https://github.com/ivoa-std/ObsCoreExtensionForRadioData.git and then consider trying what DaCHS has to offer so far; now is the time to intervene if something in the standard is not quite the way it should be (from your perspective).
The documentation for what to do in DaCHS is a bit scarce yet – in particular, there is no tutorial chapter on obs-radio, nor will there be until the extension has converged a bit more –, but if you know DaCHS' obscore support, you will be immediately at home with the //obs-radio#publish mixin, and you can see it in (very limited) action in the emi/q RD.
The FITS Media Type
I have for a long time recommended to use a media type of image/fits for FITS “images” and application/fits for FITS (binary) tables. This was in gross violation of standards: I had freely invented image/fits, and you are not supposed to invent media types without then registering them with the IANA.
To be honest, the invention was not mine (only). There are applications out there flinging around image/fits types, too, but never mind: It's still bad practice, and DaCHS 2.10 tries to rectify it by first using application/fits even where defaults have been image/fits before, and actually retroactively changing image/fits to application/fits in the database where it can figure out that a column contains a media type.
It is accepting image/fits as an alias for application/fits in SIAP's FORMAT parameter, and so I hope nothing will break. You may have to adapt a few regression tests, though.
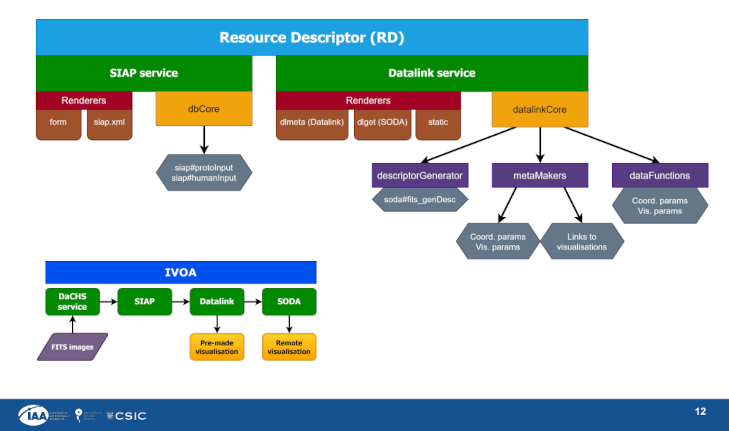
External Processing Services In Datalink
Sometimes there are non-VO services for processing datasets – imagine a cutout service as a simple example – that you can make accessible to VO clients by writing a datalink descriptor for them. So far, you could not do that with DaCHS. Since 2.10, you can. The details are discussed in External Processing Services in the reference manual, but the short version is that in the datalink core, you would define an external service from within a datalink meta maker by yielding an ExternalProcLinkDef object. See the reference documentation on the constructor arguments, where the interesting part is the inputKeys argument, which is a list of the HTTP parameters accepted by the remote service.
As an example, if there were a cutout service accepting limits in equatorial coordinates, your meta maker might look somewhat like this:
<metaMaker>
<code>
footprint = descriptor.skyWCS.calcFootprint(descriptor.hdr)
ra_range = MS(Values,
min=min(footprint[:,0]),
max=max(footprint[:,0]))
dec_range = MS(Values,
min=min(footprint[:,1]),
max=max(footprint[:,1]))
yield ExternalProcLinkDef(
descriptor.pubDID, [
MS(InputKey, name="DATASET_ID", type="text",
ucd="meta.id;meta.main",
description="Dataset to operate on",
content_=descriptor.pubDID),
MS(InputKey, name="RA_MIN",
unit="deg", ucd="pos.eq.ra;stat.min",
values=ra_range),
MS(InputKey, name="RA_MAX",
unit="deg", ucd="pos.eq.ra;stat.max",
values=ra_range),
MS(InputKey, name="DEC_MIN",
unit="deg", ucd="pos.eq.dec;stat.min",
values=dec_range),
MS(InputKey, name="DEC_MAX",
unit="deg", ucd="pos.eq.dec;stat.max",
values=dec_range)],
"http://example.org/cgi-bin/cutout.pl",
"Cutout",
"External service doing a cutout on this dataset")
</code>
</metaMaker>
On the Way To pathlib.Path
For quite a while, Python has had the pathlib module, which is actually quite nice; for instance, it lets you write dir / name rather than os.path.join(dir, name). I would like to slowly migrate towards Path-s in DaCHS, and thus when you ask DaCHS' configuration system for paths (something like base.getConfig("inputsDir")), you will now get such Path-s.
Most operator code, however, is still isolated from that change; in particular, the sourceToken you see in grammars mostly remains a string, and I do not expect that to change for the forseeable future. This is mainly because the usual string operations many people to do remove extensions and the like (self.sourceToken[:-5]) will fail rather messily with Path-s:
>>> n = pathlib.Path("/a/b/c.fits")
>>> n[:-5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'PosixPath' object is not subscriptable
So, if you don't call getConfig in any of your DaCHS-facing code, you are probably safe. If you do and get exceptions like this, you know where they come from. The solution, stringification, is rather straightforward:
>>> str(n)[:-5] '/a/b/c'
Partly as a consequence of this, there were slight changes in the way processors work. I hope I have not damaged anyone's code, but if you do custom previews and you overrode classify, you will have to fix your code, as that now takes an accref together with the path to be created.
Odds And Ends
As usual, there are many minor improvements and additions in DaCHS. Let me mention security.txt support. This complies to RFC 9116 and is supposed to give folks discovering a vulnerability a halfway reliable way to figure out who to complain to. If you try http://<your-hostname>/.well-known/security.txt, you will see exactly what is in https://dc.g-vo.org/.well-known/security.txt. If this is in conflict with some bone-headed security rules your institution may have, you can replace security.txt in DaCHS' central template directory (most likely /usr/lib/python3/dist-packages/gavo/resources/templates/); but in that case please complain, and we will make this less of a hassle to change or turn off.
You can no longer use dachs serve start and dachs serve stop on systemd boxes (i.e., almost all modern Linux boxes as configured by default). That is because systemd really likes to manage daemons itself, and it gets cross when DaCHS tries to do it itself.
Also, it used to be possible to fetch datasets using /getproduct?key=some/accref. This was a remainder of some ancient design mistake, and DaCHS has not produced such links for twelve years. I have now removed DaCHS' ability to fetch accrefs from key parameters (the accrefs have been in the path forever, as in /getproduct/some/accref). I consider it unlikely that someone is bitten by this change, but I personally had to fix two ancient regression tests.
If you use embedded grammars and so far did not like the error messages because they always said “unknown location“, there is help: just set self.location to some string you want to see when something is wrong with your source. For illustration, when your source token is the name of a text file you process line by line, you would write:
<iterator><code>
with open(self.sourceToken) as f:
for line_no, line in enumerate(f):
self.location = f"{self.sourceToken}, {line_no}"
# not do whatever you need to do on line
</code></iterator>
When regression-testing datalink endpoints, self.datalinkBySemantics may come in handy. This returns a mapping from concept identifiers to lists of matching rows (which often is just one). I have caught myself re-implementing what it does in the tests itself once too often.
Finally, and also datalink-related, when using the //soda#fromStandardPubDID descriptor generator, you sometimes want to add just an extra attribute or two, and defining a new descriptor generator class for that seems too much work. Well, you can now define a function addExtras(descriptor) in the setup element and mangle the descriptor in whatever way you like.
For instance, I recently wanted to enrich the descriptor with a few items from the underlying database table, and hence I wrote:
<descriptorGenerator procDef="//soda#fromStandardPubDID">
<bind name="accrefPrefix">"dasch/q/"</bind>
<bind name="contentQualifier">"image"</bind>
<setup>
<code>
def addExtras(descriptor):
descriptor.suppressAutoLinks = True
with base.getTableConn() as conn:
descriptor.extMeta = next(conn.queryToDicts(
"SELECT * FROM dasch.plates"
" WHERE obs_publisher_did = %(did)s",
{"did": descriptor.pubDID}))
</code>
</setup>
</descriptorGenerator>
Upgrade As Convenient
That's it for the notable changes in DaCHS 2.10. As usual, if you have the GAVO repository enabled, the upgrade will happen as part of your normal Debian apt upgrade. Still, if you have not done so recently, have a quick look at upgrading in the tutorial. If, on the other hand, you use the Debian-distributed DaCHS package and you do not need any of the new features, you can let things sit and enjoy the new features after your next dist-upgrade.
Oh, by the way: If you are still on buster (or some other distribution that still has astropy 4): A few (from my perspective minor) things will be broken; astropy is evolving too fast, but in general, I am trying to hack around the changes to make DaCHS work at least with the astropys in oldstable, stable, and unstable. However, in cases when a failure seems to be more of an annoyance to, I am resigning. If any of the broken things do bother you, do let me know, but also consider installing a backport of astropy 5 or higher – or, better, to dist-upgrade to bookworm. Sorry about that.