![[RSS]](../theme/image/rss.png)
What's new in DaCHS 2.6

The transitions of four-times ionised Technetium, with the energies of the lower and upper states on the two axes and the colour a measure of the frequency of the emitted light. Well: DaCHS 2.6 has preliminary support for LineTAP.
After six months of development, I have just released DaCHS 2.6. This blog post is the traditional discussion of major news for operators of DaCHS-based services. Also have a look at the changelog, which has finally made it to the Debian package; if you installed from package, you can now read it using zless /usr/share/doc/python3-gavo/changelog.gz.
This post's title picture alludes to LineTAP, an upcoming standard for disseminating data on specral lines intended to obviate SLAP and play nicely with VAMDC. The standard only exists as a rather preliminary draft yet, but there should be a working draft soon-ish. If you have line data to publish or can get your hands on some, consider trying //linetap#table-0 (the “-0” suggests that there will be changes, but I'd hope not terribly many).
Quite a few changes resulted from a seemingly minor user request: “How do I put a form interface in front of my EPN-TAP table?“ I rather foolishly chose to use the obscore table as an example, which was about the worst choice I could have made, as ivoa.obscore is a view in DaCHS (which means, for instance, that you can't simply add indexes), and a rather large one in Heidelberg at that (more than 80 Megarows, which means that without indexes, interactive services are impossible).
The first change in that direction was supporting form conditions over pairs of columns; you need that whenever your table has intervals in column pairs, as for instance em_min/em_max in obscore. With the new code, when users write something like 8000 .. 10000, you can instruct DaCHS to translate that into SQL computing whether or not the intervals overlap.
The spectral queries from that form still timed out, even after I had made sure there were indexes on the larger contributing tables' spectral columns. The reason for that was that the obscore mixin casted the spectral coordinates to double precision[1], and even if there is an index on a real-valued my_col, a condition like:
my_col::double precision < 4
will not use the index (unless it were over the cast expression, of course). I have hence shortened a few obscore columns (specifically, s_fov, s_resolution, em_min, em_max, em_res_power, and s_pixel_scale) to real; that's what they are in SSAP, and for now I cannot see a case where these would need to be double precision in a discovery protocol.
Having this service reminded me that registering obscore as an independent resource (rather than just as a table in a tap service's tableset) was something I've been wanting to tackle for quite a time now. This needs proper metadata, in particular coverage metadata. Determining the coverage of obscore is now possible (run dachs limits //obscore), and using codeItems (more or less explicitly), you can inject that metadata where you need it.
The cover story (“use case,” if you will) underlying this form-based service on top of obscore that started all that was that it was supposed to be friendly to optical astronomers, who by and large are still stuck with Ångström (that is, 10 − 10 m), and hence I wanted to write the spectral information in Ångström, too. In this case, the old displayUnit display hint would have done (because Obscore uses wavelengths, too), but by the time I noticed that, I had already written a spectralUnit display hint. With that, you can write something like:
<column name="e_min" unit="J" description="Lower energy in the spectrum" displayHint="spectralUnit=Angstrom"/>
This would convert e_min to Ångström when written to HTML table (but not otherwise, following the assumption that non-HTML data will be consumed by machines that have no use for legacy units).
Talking about HTML: If your root template is derived from root-tree.html (it is not unless you made it so), you have to apply a minor update to it; locate the tmpl_resDetails “script” (it's actually some HTML) in /var/gavo/web/templates/root.html. In there, there's a $description, which for the javascript templater that interprets this thing means “insert the content of the description field, properly escaping it”. Since 2.6, however, DaCHS produces these descriptions in HTML. That's progress, since these descriptions often contain links or other formatting. But it means that you have to tell the templater to not escape things: Just write $!description instead.
There are a few new things you can do in RDs. First, there are relocatable RDs: It is now recommended to have resdir="." in the opening resource (and dachs start's templates are nudging you to do that). Without that, the resource directory defaults to inputsDir/<schema>, which breaks as soon as you need to rename that directory. Now: renaming resource directories is never easy in DaCHS (for instance, because they are reflected in URLs). But for instance with mirrors, or when forking a resource, such renames happen, and relocatable RD make that a lot simpler. You can obtain the current value of the resource directory from the new \resdir macro.
Then, by popular request, you can now have index options. If you look at the documentation for create index in the postgres docs, you will notice that there are quite a few things you can do to an index. Acquainting DaCHS' index element with all of these seemed wrong to me, in particular because most of these things are only interesting in rather special circumstances beyond DaCHS' control. Instead, you can now add option elements to an index to change its behaviour, each of which can reflect some postgres configuration item. DaCHS will order your fragments so the resulting command fits Postgres' grammar.
Since this is somewhat low-level, I recommend isolating the details in userconfig. For instance, you could add streams there saying:
<STREAM id="staticindex"> <doc>For indexes on tables that never change, save about 10% storage by feeding this.</doc> <option>WITH (fillfactor=100)</option> </STREAM> <STREAM id="onfastdisk"> <doc>FEED this into an index to let it live on a fast disk</doc> <option>TABLESPACE fast</option> </STREAM>
(the second stream assumes you have set up such a tablespace). You could then configure your indexes like this:
<index columns="foo"> <FEED source="%#staticindex"/> <FEED source="%#onfastdisk"/> </index>
A feature I have put in mainly because of, say, due diligence is that you can now store the administrator password as a hash in /etc/gavo.rc. This has the advantage that people that get to read your configuration cannot (reasonably) become administrators on DaCHS' web interface; I'd consider the hash strong enough that you could put that into version control. Of course, that administrator can't do all that much in the first place.
The drawback of hashing the admin password is that then DaCHS itself cannot use the password to authenticate against a running server. That is not a disaster, but it will keep it from automatically discarding the root page on changes and automatically clearing a few caches when you import a resource.
As usual, there are many other changes; let me mention
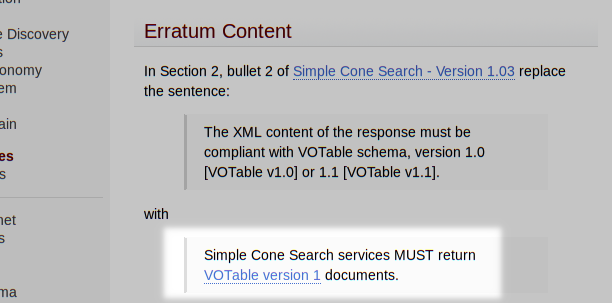
- the modern VOTables from SCS I have celebrated here before,
- the makeIAUId(prefix, long, lat) rowmaker function that makes creating IAU-compliant identifiers a bit simpler,
- a function utils.formatFloat that may be helpful when producing human-readable floating-point numbers (it's not in gavo.api yet, but I think it will migrate there),
- the statistics property on columns that you can set to enumerate on TEXT-typed columns to make DaCHS collect preliminary statistics on those (more on that in a later post),
- the -d option to dachs limits to dump the column statistics DaCHS has gathered (see the DaCHS 2.4 announcement for more on these stats), and
- that the maximum order of a MOC is now given in ASCII-MOCs DaCHS produces.
With this: If you have GAVO's repository enabled, you will get DaCHS 2.6 with the next apt upgrade. I will also try to get it into the Debian backports, too, and if I manage that, you will read about it on this blog.
| [1] | In case you wonder why it did that: The obscore mixin basically fills out templates like: CAST(\em_min AS real) AS em_min, CAST(\em_max AS real) AS em_max, where the macro replacements are taken from whatever you give in the mixin's parameters. Now, if \em_min happens to work out to NULL, Postgres just picks any old type (text, IIRC) for the corresponding column. That is not a problem until the result of that table definition is UNION-ed together with another table where \em_min is a proper floating point number: Postgres will then complain about incompatible types in a union. To avoid that, I must give a type to anything contributing to the obscore view. |