![[RSS]](./theme/image/rss.png)
DaCHS 2.1: Say hello to Python 3

Today, I have released DaCHS 2.1, the first stable DaCHS running on Python 3. I have tried hard to make the major version move painless and easy, and indeed “pure DaCHS” RDs should just continue to work. But wherever there's Python in your RDs or near them, things may break, since Python 3 is different from Python 2 in some rather fundamental ways.
Hence, the Debian package even has a new name: gavodachs2-server. Unless you install that, things will keep running as they do. I will keep fixing serious DaCHS 1 bugs for a while, so there's no immediate urgency to migrate. But unless you migrate, you will not see any new features, so one of these days you will have to migrate anyway. Why not do it today?
Migrating to DaCHS 2
In principle, just say apt install gavodachs2-server and hope for the best. If you have a development machine and regression tests defined, this is actually what we recommend, and we'd be very grateful to learn of any problems you may encounter.
If you'd rather be a little more careful, Carlos Henrique Brandt has kindly updated his Docker files in order to let you spot problems before you mess up your production server. See Test Migration for a quick intro on how to do that. If you spot any problems that are not related to the Python 3 pitfalls mentioned in the howto linked below or nevow exodus, please tell me or (preferably) the dachs-support mailing list.
A longer, more or less permanent piece elaborating possible migration pains, is in our how-to documentation: How do I go from DaCHS1 to DaCHS2?
What's new in DaCHS2?
I've used the opportunity of the major version change to remove a few (mis-) features that I'm rather sure nobody uses; and there are a few new features, too. Here's a rundown of the more notable changes:
- DaCHS now produces VOTable 1.4 by default. This is particularly notable when you provide TIMESYS metadata (on which I'll report some other time).
- When doing spatial indices, prefer the new //scs#pgs-pos-index to //scs#q3cindex. While q3c is still faster and more compact than pgsphere when just indexing points, on the longer run I'd like to shed the extra dependency (note, however, that the pgsphere index limits the cone search to a maximum radius of 90 degrees at this point).
- Talking about Cone Search: For custom parameters, DaCHS has so far used SSA-like syntax, so you could say, for instance, vmag=12/13 (for “give me rows where vmag is between 12 and 13”). Since I don't think this was widely used, I've taken the liberty to migrate to DALI-compliant syntax, where intervals are written as they would be in VOTable PARAM values: vmag=12 13.
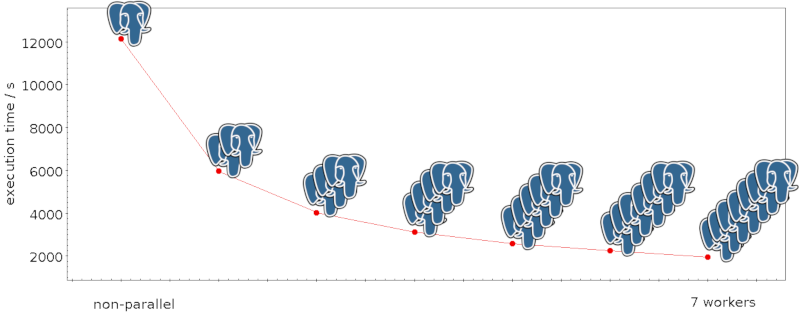
- In certain situations, DaCHS tries to enable parallel queries (previously on this blog).
- Some new ADQL user defined functions: gavo_random_normal, gavo_mocintersect, and gavo_mocunion. See the TAP capabilities for details, and note that the moc functions will fail until we put out a new pgsphere package that has support for the MOC-MOC operations.
- dachs info (highly recommended after an import) now takes a --sample-percent option that helps when doing statistics on large tables.
- For SSA services serving something other than spectra (in all likelihood, timeseries), you can now set a productType meta as per the upcoming SimpleDALRegExt 1.2.
- If you have large, obscore-published SIAP tables, re-index them (dachs imp -I q) so queries over s_ra and s_dec get index support, too.
- Since we now maintain RD state in the database, you can remove the files /var/gavo/state/updated* after upgrading.
- When writing datalink metaMakers returning links, you can (and should, for new RDs) define the semantics in an attribute to the element rather in the LinkDef constructor.
- Starting with this version, it's a good idea to run dachs limits after an import. This, right now, will mainly set an estimate for the number of rows in a table, but that's already relevant because the ADQL translator uses it to help the postgres query planner. It will later also update various kinds of column metadata that, or so I hope, will become relevant in VODataService 1.3.
- forceUnique on table elements is now a no-op (and should be removed); just define a dupePolicy as before.
- If you write bad obscore mappings, it could so far be hard to figure out the reason of the failure and, between lots of confusing error messages, to fix it. Instead, you can now run ``dachs imp //obscore recover`` in such a situation. It will re-create the obscore table and throw out all stanzas that fail; after that, you can fix the obscore declarations that were thrown out one by one.
- If you run DaCHS behind a reverse proxy that terminates https, you can now set [web]adaptProtocol in /etc/gavo.rc to False. This will make that setup work for form-based services, too.
- If you have custom OAI set name (i.e., anything but local and ivo_managed in the sets attribute of publish elements), you now have to declare them in [ivoa]validOAISets.
- Removed things: the docform renderer (use form instead), the soap renderer (well, it's not actually removed, it's just that the code it depends on doesn't exist on python3 any more), sortKey on services (use the defaultSortKey property), //scs#q3cpositions (port the table to have ra and dec and one of the SCS index mixins), the (m)img.jpeg renderers (if you were devious enough to use these, let me know), and quite a few even more exotic things.
Some Breaking Changes
Python 3 was released in 2008, not long after DaCHS' inception, but since quite a few of the libraries it uses to do its job haven't been available for Python 3, we have been reluctant to make the jump over the past then years (and actually, the stability of the python2 platform was a very welcome thing).
Indeed, the most critical of our dependencies, twisted, only became properly usable with python3 in, roughly, 2017. Indeed, large parts of DaCHS weren't even using twisted directly, but rather a nice add-on to it called nevow. Significant parts of nevow bled through to DaCHS operators; for instance, the render functions or the entire HTML templating.
Nevow, unfortunately, fell out of fashion, and so nobody stepped forward to port it. And when I started porting it myself I realised that I'm mainly using the relatively harmless parts of nevow, and hence after a while I figured that I could replace the entire dependency by something like a 1000 lines in DaCHS, which, given significant aches when porting the whole of nevow, seemed like a good deal.
The net effect is that if you built code on top of nevow – most likely in the form of a custom renderer – that will break now, and porting will probably be rather involved (having ported ~5 custom renderers, I think I can tell). If this concerns you, have a look at the README in gavo.formal (and then complain because it's mainly notes to myself at this point). I feel a bit bad about having to break things that are not totally unreasonable in this drastic way and thus offer any help I can give to port legacy DaCHS code.
Outside of these custom renderers, there should just be a single visible change: If you have used n:data="some_key" in nevow templates to pull data from dictionaries, that won't work any longer. Use n:data="key some_key" n:render="str" instead. And it turns out that this very construct was used in the default root template, which you may have derived from. So – see if you have /var/gavo/web/templates/root.html and if so, whether there is <ul n:data="chunk" in there. If you have that, change it to <ul n:data="key chunk".
Update (2020-11-19): Two only loosely related problems have surfaced during updates. In particular if you are updating on rather old installations, you may want to look at the points on Invalid script type preIndex and function spoint_in already exists in our list of common problems.