2018-10-10
Markus Demleitner
The other day I gave one of my improvised live demos (“What, roughly,
are you working on?”) and I ended up needing to translate identifiers
from the Henry Draper Catalogue to modern positions. Quickly typing
“Henry Draper” into TOPCAT's TAP search window didn't yield anything
useful (some resources only using the HD, and a TAP service that
didn't support uploads – hmpf).
Now, had I tried the somewhat more thorough WIRR Registry interface,
I'd have noted the HD catalogue at VizieR
and in particular Fabricius' et al's HD-Tycho 2 match
(explaining why they didn't show up in TOPCAT is a longer story; we're working
on it). But alas, I didn't, and so I set out to produce a catalogue
matching HD and Gaia DR2, easily findable from within TOPCAT's TAP
client. Well, it's here in the form of the hdgaia.main table in our data center.
Considering the nontrivial data discovery and some yak shaving I had to
do to get from HD identifiers to Gaia DR2 ones, it was perhaps not as
futile an exercise as I had thought now and then during the preparation
of the thing. And it gives me the chance to show a nice ADQL technique
to locate outliers.
In this case, one might ask: Which objects might Annie Cannon and
colleagues have misclassified? Or perhaps the objects have changed their
spectrum between the time Cannon's photographic plates have been taken
and Gaia observed them? Whatever it is: We'll have to figure out where
there are unusual BP-RPs given the spectral type from HD.
To figure this out, we'll first have to determine what's “usual”. If
you've worked through our ADQL course,
you know what to expect: grouping. So, to get a table of average colours
by spectral type, you'd say (all queries executable on the TAP service
at http://dc.g-vo.org/tap):
select spectral,
avg(phot_bp_mean_mag-phot_rp_mean_mag) as col,
count(*) as ct
from hdgaia.main
join gaia.dr2light
using (source_id)
group by spectral
– apart from the join that's needed here because we want to pull
photometry from gaia, that's standard fare. And that join is the selling
point of this catalog, so I won't apologise for using it already in the
first query.
The next question is how strict we want to be before we say something
that doesn't have the expected colour is unusual. While these days you
can rather easily use actual distributions, at least for an initial
analysis just assuming a Gaussian and estimating its FWHM as the
standard deviation works pretty well if your data isn't excessively
nasty. Regrettably, there is no aggregate function STDDEV in ADQL (you
could still ask for it: head over to the DAL mailing list before ADQL 2.1 is a
done deal!). However, you may remember that
Var(X)=E(X2)-E(X)2, that the average is an estimator
for the expectation, and that the standard deviation is actually an
estimator for the square root of the variance. And that these estimators
will work like a charm if you're actually dealing with Gaussian data.
So, let's use that to compute our standard deviations. While we are at
it, throw out everything that's not a star, and
ensure that our groups have enough members to make our estimates
non-ridiculous; that last bit is done through a HAVING clause that
essentially works like a WHERE, just for entire GROUPs:
select spectral,
avg(phot_bp_mean_mag-phot_rp_mean_mag) as col,
sqrt(avg(power(phot_bp_mean_mag-phot_rp_mean_mag, 2))-
power(avg(phot_bp_mean_mag-phot_rp_mean_mag), 2)) as sig_col,
count(*) as ct
from hdgaia.main
join gaia.dr2light
using (source_id)
where m_v<18
group by spectral
having count(*)>10
This may look a bit scary, but if you read it line by line, I'd argue
it's no worse than our harmless first GROUP BY query.
From here, the step to determine the outliers isn't big any more. What
the query I've just written produces is a mapping from spectral type to
the means and scales (“µ,σ” in the rotten jargon of astronomy) of the
Gaussians for the colors of the stars having that spectral type. So, all
we need to do is join that information by spectral type to the original
table and then see which actual colors are further off than, say, three
sigma. This is a nice application of the common table expressions I've
tried to sell you in the post on ADQL 2.1;
our determine-what's-usual query from above stays nicely separated from
the (largely trivial) rest:
with standards as (select spectral,
avg(phot_bp_mean_mag-phot_rp_mean_mag) as col,
sqrt(avg(power(phot_bp_mean_mag-phot_rp_mean_mag, 2))-
power(avg(phot_bp_mean_mag-phot_rp_mean_mag), 2)) as sig_col,
count(*) as ct
from hdgaia.main
join gaia.dr2light
using (source_id)
where m_v<18
group by spectral
having count(*)>10)
select *
from hdgaia.main
join standards
using (spectral)
join gaia.dr2light using (source_id)
where
abs(phot_bp_mean_mag-phot_rp_mean_mag-col)>3*sig_col
and m_v<18
– and that's a fairly general pattern for doing an initial outlier
analysis on the the remote side. For HD, this takes a few seconds and
yields 2722 rows (at least until we also push HDE into the table). That
means you can keep 99% of the rows (the boring ones) on the server and
can just pull the ones that could be interesting. These 99% savings
aren't terribly much with a catalogue like the HD that's small by
today's standards. For large catalogs, it's the difference between a
download of a couple of minutes and pulling data for a day while
frantically freeing disk space.
By the way, that there's only 2.7e3 outliers among 2.25e5 objects, while
Annie Cannon, Williamina Fleming, Antonia Maury, Edward Pickering, and
the rest of the crew not only had to come up with the spectral
classification while working on the catalogue but also had to classify
all these objects manually. This is an amazing feat even if all of those
rows actually were misclassifications (which they certainly aren't) –
the machine classifiers of today would be proud to only get 1% wrong.
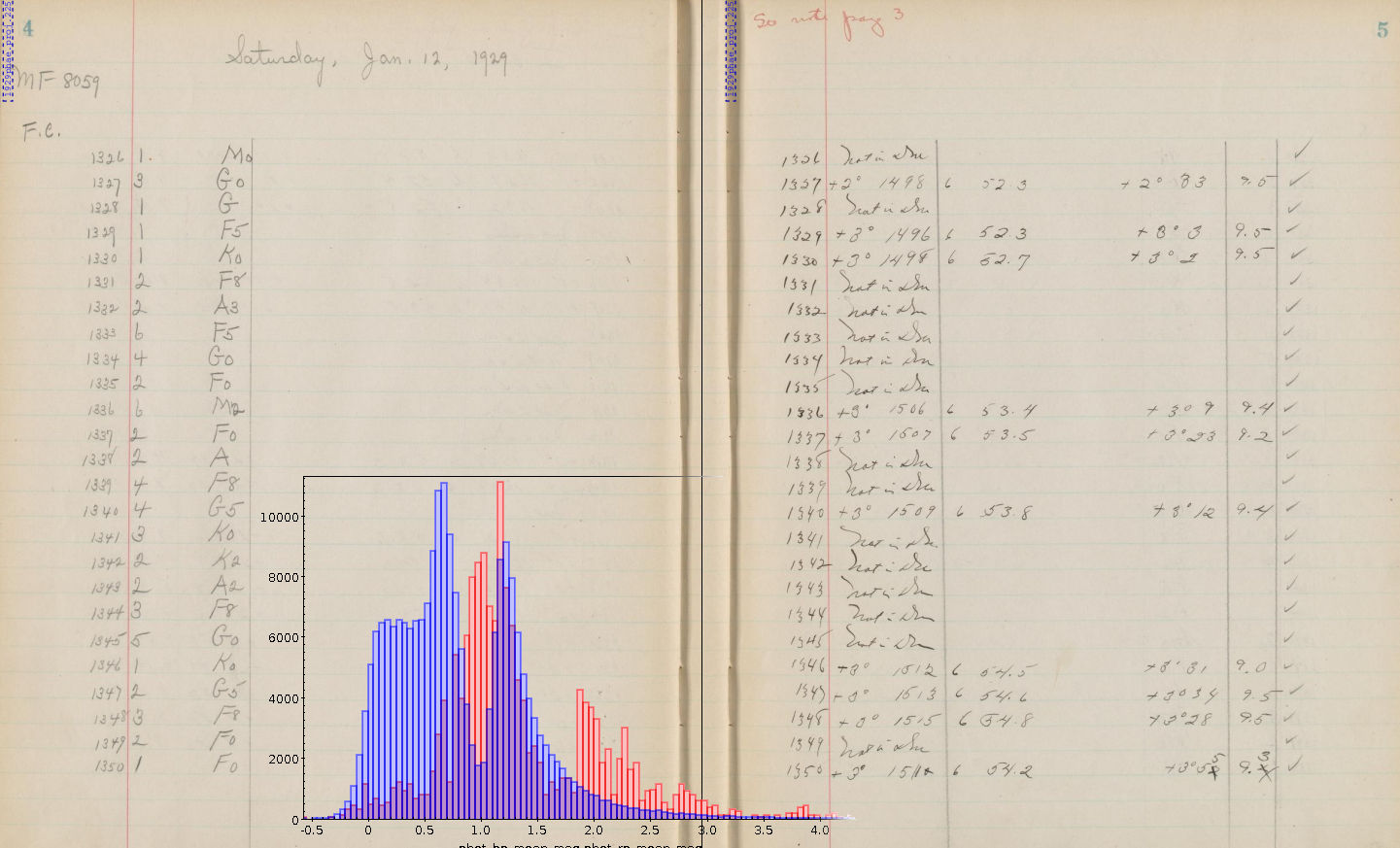
The inset in the facsimile of Annie Cannons notebooks above shows how
the outliers are distributed in color space relative to the full
catalogue, where the basic catalogue is in blue and the outliers (scaled
by 70) in red. Wouldn't it make a nice little side project to figure out
the reason for the outlier clump on the red side of the histogram?

![[RSS]](./theme/image/rss.png)

![[Screenshot: graphs and numbers]](/media/stats_gregory.png)