
![[RSS]](../theme/image/rss.png)
Another Virtual Interop
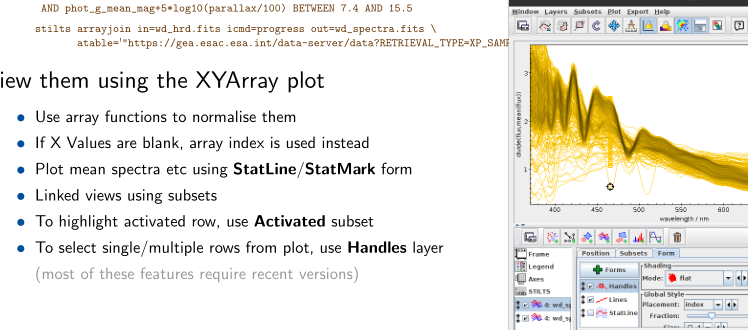
One thing you could learn at this interop: How to identify the source row of a line in the TOPCAT's XYArray plot. See the end of this post for where this comes from.
It's Interop time again! That is, most of the people involved in developing the Virtual Observatory (or for it) will report on what they have been up to since the last Interop, and what they are planning for the near-ish future. It is again an online meeting, so if interested, you could still register and then attend a couple of our sessions.
You will see me as a chair (but for the first time since I became chair there not as a speaker) in Semantics, and I'll have talks in Registry (obligatorily) and DAL 1, though regular readers of this blog will have a few déjà vus.
I plan to update this post as the meeting progresses – so, perhaps check back a few times until thursday.
Update 2022-10-18, 15:00 UTC: I was expecting the VO in the Cloud Plenary with quite a bit of anxiety, because “in the cloud“ these days tends to mean “stuff things into proprietary walled gardens“. The first input talk turned out to be quite a bit less scary: Data providers want to have links to commerical cloud providers in addition to http download links. That's reasonable given users may want to optimise accesses for large data sets, and seeing that most respondents pointed to Datalink as the way to do that (as I did) was nice. The devil is in the details, though: Making good concepts that let clients figure out what are, in a sense, “equivalent“ ways to obtain the data is probably hard. The one thing I'm sure about is that I don't want concepts like #aws-metadata in datalink/core.
And the rest of the session was rather a “how VO standards are or may be useful to us“ rather than the “dump the old open rubbish and move on to walled gardens“ I was worrying about. So… excellent!
Update 2022-10-18, 21:10: Sitting in the DAL 1 Session, I am seriously tempted to become a gardener while listening to Tom's talk on Firewalls against ADQL. I have to thank U Heidelberg for hosting our services without horrible “Web Application Firewalls“ or trying to hack into https connections to “sanitise“ requests. At STScI, it seems the density of snake oil “security appliances“ is so high that at least somewhat advanced network usage like TAP and ADQL becomes really shaky.
Can we just genrally disarm and perhaps, if SQL injection really is a problem in individual cases, just hire programmers on permanent contracts (meaning: they'll aquire sufficient experience) and/or reviewers for the software we run facing the net? It's not like SQL injection is just bad luck. It's a bug in every single case, and a sort of bug that's relatively simple to avoid – simpler in any case than detecting SQL injection attempts with a reasonable false-positive rate.
Update 2022-10-20, 5:00 UTC: Yesterday, I had reasons both for rejoicing and for wishing for a brown bag. The rejoicing part was (for instance) in the solar system session, where Steve Joy reported on getting PDS Planetary Plasma Interactions (PPI) data into the VO – that's a good thing no matter what, especially given that I have a very soft spot for solar system data anyway. As the main author of DaCHS, however, I was particularly happy to see PPI are using it to talk to the VO. DaCHS thus is now running in Los Angeles, too. Hollywood, practically.
The brown bag moment came in the Registry session; while my talks I think went fine – one of them basically being the oral version of a post from this blog –, Tom's talk on pyvo.registry made me cringe because he pointed out a bad interoperability sin on my side. The problem was not that my code unconcernedly uses COALESCE. From private mails I had understood, perhaps somewhat over-optimistically, that RegTAP operators had greenlighted that after my DAL post from last December, and it's a really simple extension anyway. I give you, though, that I should have ensured that COALESCE really had arrived on the servers before pushing for merging the new regsearch code into pyVO.
No, what's really embarrassing is the UNION business. You see, the regsearch keyword constraint looks for the words in multiple places, and so it does something conceptually like WHERE keyword matches table1.descripition OR keyword matches table2.subject. Such cross-table ORs are generally extremely hard to plan for the database server, and thus when I re-wrote query generation for the RegTAP keyword search I just put in UNION – queries are really two orders of magnitude faster on my server this way.
However, UNION has not been part of ADQL 2.0, and although I've lobbied for the set operators for a about a decade now, they are not formally part of ADQL yet. They will be part of ADQL 2.1, but even then they will not be mandatory. Hence, I should not blindly have employed UNION in code supposed to be interoperable, even less so because I can actually programmatically figure out whether a service supports UNION (from the TAP capabilities) and hence could have put in a fallback for where it's unavailable. Aw, dang.
Update 2022-10-20, 20:00 UTC Just two sessions to go – Radio and Closing, though that little rest will be a challenge, with the closing session ending at 1 am my time.
Thus, in the midnight hour, for the Semantics working group I will report on our session, which had quite a bit of rather deep plumbing this time. For instance, for the update to our standard on unit syntax, Norman raised the question whether “%“ ought to be a legal unit, and if so, if there's any way to keep ppm, ppb, and ppt out (؉ or ‰, on the other hand, are easy to keep out: We're really stubbornly insisting on pure ASCII). This may border on bikeshedding, but it has very concrete consequences on clients (such as astropy's unit parser) and services (where, for instance, VizieR has to cope with submissions that have columns given in percent). Before the session, it looked like we'd just let in percent, and that only grudgingly. Now… it's likely we will have to be more liberal.
Great news in the session was that there is now a prototype of a Rosetta Stone for facility names in Paris, that is, a service that lets you map between all the different names your typical observation facility has (for instance, the part of my institute that is up on the mountain could be known as Königstuhl Observatory, Landessternwarte Königstuhl, LSW, Zentrum für Astronomie Heidelberg, and much more). If you have never tried linking all these various names up, you will be surprised how hard that problem is. See Baptiste's slides for how they are tackling it and how they are applying hardcore Semantics tech – in particular, SPARQL – to do it. I liked it a lot.
Another talk I would like to call out is Steve Crawford's from the session of the Data Curation and Preservation IG. His recommendation to go with CC0 for, well, licensing, is something I can only support exactly because it is not a licence at all, which relieves you of the troublesome problem of assinging copyright so someone. That triviality is only the first of several legal problems we have since we have put the IVOA documents under CC-BY. But since nobody is ever going to court about any of this, the legal trouble is perhaps not terribly worrying. What is nasty about CC-BY is that whatever is licensed CC-BY is (generally) incompatible with the GPL and many other software licenses, which means you will get in trouble if you try to package it with something destined for Debian. And Steve makes some excellent points why CCO is just fine for science data.
Finally, if you liked the posts on array plotting in TOPCAT and usage in ADQL, you should definitely have a look at Mark's talk in this morning's Apps session, where he in particular shows how you can go from a line in the array plot back to the row that contains the array.
And with that I've told you where the opening slide fragment came from. Good night!